计算机的相关计算
进制的转换
首先可以先把2的0~10次方背一下。
存储的单位转换
计算机体系结构
运算器
控制器
存储器
输出设备
输入设备
控制器主要组成的部件
程序计数器pc:存放下一条指令的地址
程序寄存器IR:存放当前执行的命令
指令译码器ID:分析命令中的操作码
地址寄存器AR:保存CPU目前访问的内存单元的地址
时序部件:控制各个部件的有序协调
运算器主要组成部件
算数逻辑单元ALU:执行算数和逻辑的运算
累加寄存器AC:暂时存放算数中间的结果
数据缓冲寄存器:存放一条指令或顺序
状态条件寄存器:保存运算中各种标志位信息
多路转换器:对送入加法器的数据进行选择和控制的电路
指令系统基础
指获得操作数的方法。在指令系统中可采用多种寻址分数,用以实现扩大寻址空间并提高编程灵活性的目的
操作码:指明该指令完成的操作,如取数、做加法或输出数据等
地址码:指明操作数的内容或所在的存储单元地址
寻址方式
立即寻址
变址寻址
直接寻址
间接寻址
寄存器寻址
寄存器间接寻址
直接寻址和立即寻址是计算机指令系统中两种不同的寻址方式,主要区别如下:
定义
直接寻址
直接寻址是一种基本的寻址方式,在这种方式下,指令中直接给出操作数所在内存单元的地址。CPU 根据这个地址从内存中读取相应的操作数进行处理。
例如,在某条汇编指令中,指令指明操作数存放在内存地址为 2000H 的单元中,CPU 就会直接访问 2000H 这个内存地址来获取操作数。
立即寻址
立即寻址是指操作数直接包含在指令中,即指令的操作码后面紧跟着的就是操作数本身,而不是操作数的地址。当执行该指令时,CPU 直接从指令中取得操作数,无需再到内存中去查找。
例如,指令 “MOV AX, 1234H”,这里的 1234H 就是立即数,它直接作为操作数被传送到寄存器 AX 中。
操作数位置
直接寻址
操作数存放在内存中,指令中给出的是该操作数在内存中的具体地址。CPU 需要根据这个地址访问内存来获取操作数,涉及到内存的读写操作,速度相对较慢。
立即寻址
操作数直接包含在指令代码中,与指令一起存放在内存的代码段中。当 CPU 从内存中取出指令时,同时也就获得了操作数,不需要额外的内存访问操作来获取操作数。
灵活性
直接寻址
可以访问内存中的任意地址,只要该地址在 CPU 可寻址的范围内。这使得程序可以灵活地处理存放在不同内存位置的数据,适合处理需要动态变化数据的情况,例如数组、变量等。但如果需要频繁访问不同地址的数据,每次都要修改指令中的地址字段,编程相对复杂。
立即寻址
操作数是固定在指令中的,一旦指令确定,操作数也就确定了,无法在程序运行过程中动态改变。因此,立即寻址的灵活性较差,通常用于给寄存器或内存单元赋一个固定的初始值,或者进行一些简单的常量计算。
指令长度
直接寻址
由于指令中需要包含操作数的内存地址,而内存地址通常需要一定的位数来表示(例如在 16 位系统中可能需要 16 位,在 32 位系统中可能需要 32 位),所以指令长度相对较长。
立即寻址
指令长度主要取决于操作码和立即数的长度。如果立即数较小,占用的位数较少,指令长度可能相对较短。但如果立即数较大,也会增加指令的长度。
执行速度
直接寻址
由于需要访问内存来获取操作数,涉及到内存的读写操作,而内存的访问速度相对 CPU 内部的寄存器和运算单元来说较慢,所以直接寻址的执行速度相对较慢。
立即寻址
操作数直接包含在指令中,CPU 无需额外的内存访问操作,因此执行速度较快,能够快速完成指令的执行。
常见的寻址方式的特点
指令系统类型
两种指令集系统
CISC(复杂):
指令:数量多,使用频率差别打可变长格式
寻址方式:支持多种
实现方式:微程序控制技术
RISC(精简):
指令:数量少,使用频率接近,定长格式,大部分为单周期指令
寻址方式:支持方式少
实现方式:增加了通用寄存器;硬布线逻辑控制为主;适合采用流水线。
CISC和RISC的特点对比
fly分类方法
流水线技术
取指->分析->执行
未使用流水技术执行指令的情况
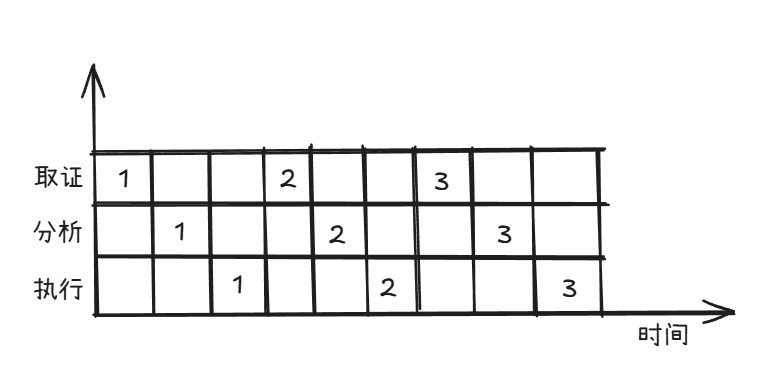 使用流水线执行指令的情况
使用流水线执行指令的情况
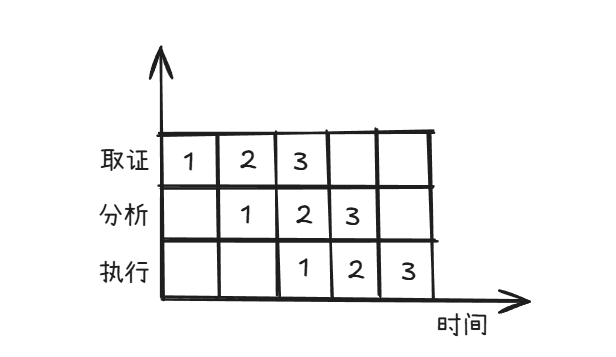
流水线周期
各流水线中执行时间最长的那一段
流水线时间的计算
n条指令,采用流水线其执行时间为:(t1+t2+t3)+(n-1)t
其中的t是流水周期,它是t1/t2/t3中最长的那一段。
流水线技术指标
吞吐率:单位时间内流水线完成的任务数量,Tp=n/Tk
n表示指令条数,Tk表示处理n条指令所需要的时间。
理论上最大的吞吐率是: 1/流水线周期。
加速比:不使用流水线所用的时间与使用流水线所用的时间比即为加速比。
效率:流水线的设备利用率称为流水线效率。(采用流水线完成n个任务占用的的时空区域有效面积与所占区域总面积之比)。
注:各段流水时间相同,就越能提升流水线的性能
存储器系统
多级存储结构
采用多级存储结构的目的:解决存储容量、成本和速度之间的矛盾的问题
CPU(寄存器)
cache:按内容存取(相联存储器)
内存(主存):RAM和ROM
外存:硬盘、光盘、U盘等
cache缓存->主存层次和主存->辅存层次
局部性原理:是层次化存储结构的支撑
时间局部性:刚被访问的内容,立即又被访问。
空间局部性:刚被访问的内容,临近的空间很快被访问。
主存
简称“主存”,起作用是存放指令和数据,并能有中央处理器(CPU)直接随机存取。主要有随机存储器RAM和只读存储器ROM组成,主要为DRAM组成
芯片类型
闪速存储器(Flash Memory):简称闪存,在不加电的情况下能长时间保存存储的信息,它既有ROM的特点,又有很高的存取速度,而且易于擦除和重写,功耗很小,也可用作固态大容量存储器的存储芯片。
主存容量
采用随机存取方式存储,对每个存储内存单元进行编址
地址编号通常采用16进制表示。
主存容量=存储单元的个数*存储单元的容量
表示存储容量的相关单位
位:用bit表示,一个二进制表示1bit;
字节:用B表示,,1B=8bit;
字:通常位字节的整数倍,常见的字长有8/16/32/64bit;实际表示CPU一次处处理的二进制位数;
K:1K=210
M:1M=210K=220
G:1G=210M=220K=230
存储芯片片数计算
主存的总容量,实际上又是一片或多片存储芯片配以控制电路构成的,因此可知:
存储芯片片数=主存总容量/单个存储芯片容量1
Cache
Cache高速缓冲寄存器是位于CPU和主存之间,容量较小,当速度很高的的存储器,通常由SRAM组成。
Cahe利用局部性原理,将主存中可能被访问的内容调入速度更快的cache中,以解决CPU和主存之间速度不匹配的问题,而进行提升计算机性能。
映射方式
三种映射方式的比较
注:主存于Cache之间的地址映射直接由硬件自动完成。
Cache命中率
Cache 命中率指 CPU 访问数据时,所需数据在 Cache 中直接命中的概率,计算公式为:
命中率 = 命中次数 / 总访问次数
命中率越高,说明 Cache 的有效性越强,CPU 访问主存的次数越少,系统性能越优。
Cache淘汰算法
、
硬盘
硬盘接口
按照硬盘材质分位两大类
HDD:传统硬盘,即机械硬盘
SSD:固态硬盘
固态硬盘SSD的组成
固态硬盘SSD:可采用2种芯片类型,FLASH芯片或DRAM芯片
各类存储器的存取方式
相联存储:按内容存取(Cache)
随机存储:有地址,与位置无关(内存、U盘)
直接存储:有地址,与位置有关(硬盘、软盘、光盘)
顺序存储:无地址(磁盘)

